|
Open CASCADE Technology
6.8.0
|
|
|
Open CASCADE Technology
6.8.0
|
|
Please note that this document describes use of WOK as comprehensive build system. This use is outdated, and WOK is to be removed in one of the future OCCT releases.
Currently only a small subset of WOK capabilities described in this document is actually necessary for building OCCT. See Using WOK for a more practical guide.
Open CASCADE Technology (OCCT) development environment is able to accommodate large numbers of developers working on a variety of products. Within this environment developers can produce multiple versions of products for various hardware and software platforms, including versions corresponding to particular marketing requirements. At the same time, OCCT development environment enables the maximum possible reuse of software components. In other words, OCCT development environment is designed to facilitate industrial scale development.
The following diagram shows OPEN CASCADE tools and resources, the development method, and the architecture of applications that you can develop with Open CASCADE Technology.
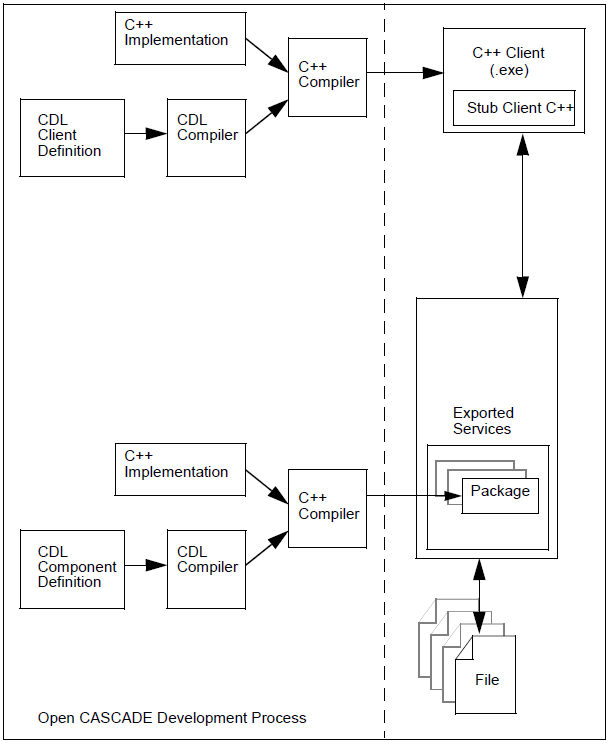
The developer defines new software components in CDL, Component Description Language, and uses a CDL compiler to derive their C++ implementations. These components are then compiled into packages.
The WOK environment is made up of entities, for example software factories and development units. A full list of WOK entities is provided in the Glossary section.
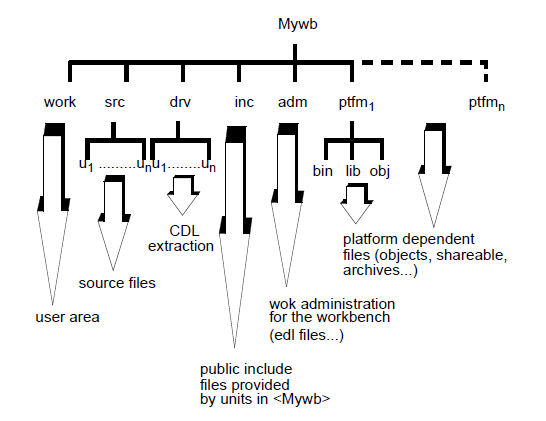
WOK manages two different types of files: user source files and WOK administration files. To support this, each entity has a home directory, which contains its administration directory. This is called adm and stores the administration files that WOK needs. In addition development units have a source directory called src, which contains both .cdl and .cxx source files, and a header file directory called inc, which contains .hxx files.
A development unit is the smallest unit that can be subject to basic development operations such as modifying, compiling, linking and building. The following list contains all types of development units. The letter in parentheses indicates the letter key by commands such as ucreate and umake. In the rest of the manual, this letter key is referred to as the short key.
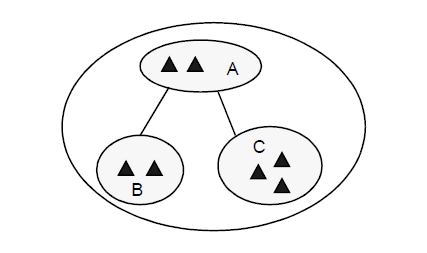
A workbench is a specialized directory structure where the user creates, modifies, and uses development units. A workbench is likely to be the personal property of one user or at most a small team of developers.
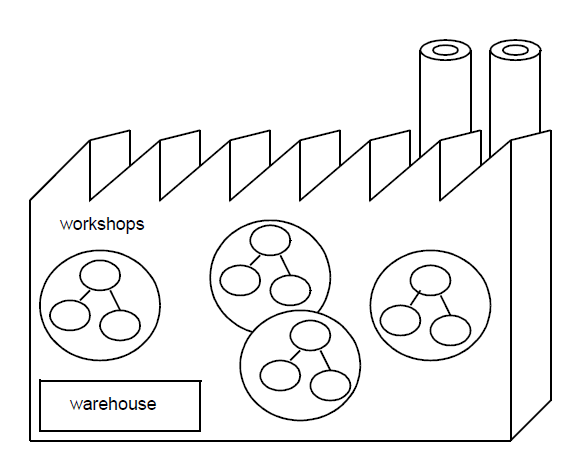
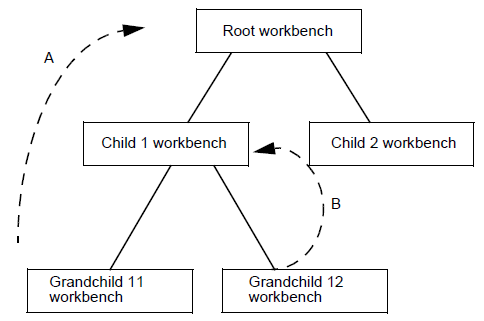
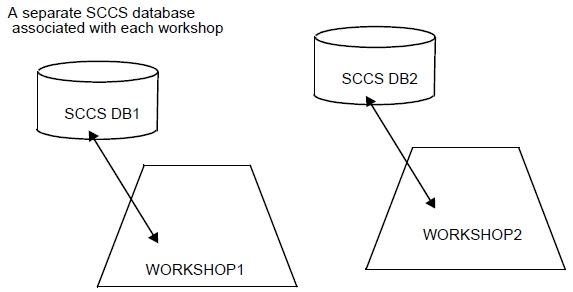
A workshop is a tree of workbenches. It provides the development team with an independent workspace inside which the complete cycle of software production can be carried out. The root workbench is in a valid state and contains the working versions of the development units. Development units in a root workbench are visible in its child workbenches.
For example, the schema below shows a workshop containing three workbenches. Workbenches B and C are the children of workbench A. Development units in A are visible in both B and C
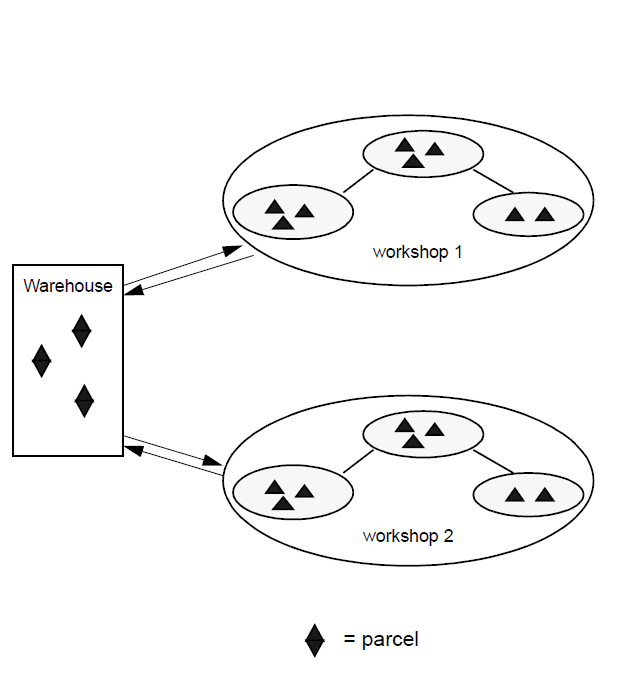
A factory is a set of workshops and their corresponding warehouse. There is a single warehouse in any factory. The continuous upgrading and improvement of a product is carried out in a specific factory. To create a new version of an application within the factory, you establish a new workshop dedicated to creation and support of the new version.
A development unit is the basic element of WOK development. It includes the following three entities:
The directory structure of a development unit consists of a tree of directories, which are created when the development unit is initialized. Refer to the Workbenches section for further details on the workbench structure.
Source files are written by the developer in the source section (the src directory) of the development unit. Each development unit maintains the description of its own source files, and this description is stored in one or more files within the src directory. The details of how the description is stored vary according to development unit type as shown below:
Derived files created by compilation are automatically placed in the derived section of the development unit. These may be executable files or archives of compilation results.
A package is a development unit that defines a set of classes, which share a number of common features such as similar data structure or a set of complementary algorithmic services. Packages help to manage creation and the use of large hierarchies of software components. To create a package, you write a .cdl file describing it in the src directory of the package development unit. The description includes classes and global methods, which comprise it. Each class is also described in a separate .cdl file. The package .cdl file also lists the packages used in the specification of its classes and methods. C++ implementation files are also stored in the src subdirectory of the package development unit. These implementation files are:
To create the Development Unit structure for a package use the following syntax:
The package description has the following CDL syntax:
For example:
For full details on the CDL syntax, refer to the CDL User’s Guide.
A schema is a development unit that defines the set of all data types, which your application is likely to need in order to read and write files. Such data types are persistent.
To create a schema, write a .cdl file that lists all the packages, which contain all persistent data types used by the application. Note that only persistent classes are taken into account during compilation; transient classes are ignored.
Note that you don’t have to put dependencies in all packages and classes. You only have to write the highest level dependencies. In other words, the uses keyword in the schema file allows you to list packages. Any package similarly listed in the package files for these packages are also incorporated into the schema.
To create the Development Unit structure for a schema use the syntax below:
The schema description has the following CDL syntax :
For example:
For full details on the CDL syntax, refer to the CDL User’s Guide.
The purpose of an executable is to make executable programs. The executable can use services from one or more packages and is described in a .cdl file as a set of packages.
To create an executable, you write one or more MyExe.cxx files in the src subdirectory of the unit. This file will contain the main function. Then it is possible to compile the executable.
To create the Development Unit structure for an executable, use the syntax below:
The executable description has the following CDL syntax:
For example:
For full details on the CDL syntax, refer to the CDL Reference Manual.
A toolkit is a development unit that groups a set of packages to create a shareable library. An example of a toolkit is the ModelingData module. Toolkits serve for the following purposes:
A toolkit has no CDL definition. Creating a toolkit involves writing a PACKAGES file in the src subdirectory of its development unit. This file lists all the packages needed in the toolkit. You then create a definition of this file to the FILES.
You then compile the toolkit to create a shareable library.
A nocdlpack is a development unit that has no CDL definition. It is compiled directly from source files written in C, C++, Fortran, or in sources to be treated by the lex or yacc tools. A nocdlpack is useful when you write a low-level interface with another product, for example, a network application.
To define a nocdlpack, you create a file called FILES in the src subdirectory of the nocdlpack development unit. In this file, you list the Fortran, C, C++, lex, and yacc files that compose the pack. You list the files one per line.
On compilation, the result is a shareable library.
An interface is a development unit that defines a set of services available for wrapping into Java. An interface is defined in a .cdl file as a list of packages, package methods, classes, and methods. It makes these available to a jni unit.
To create the Development Unit structure for an interface, use the syntax below:
The interface description has the following CDL syntax:
For example:
A jni is a development unit that wraps declared services into Java using JNI (Java Native Interface).
A jni creates Java classes that are used as C++ counterparts when developing in Java.
To create the Development Unit structure for an Jni, use the syntax below: ucreate -j MyJni
The interface description has the following CDL syntax:
For example :
The delivery process allows creating parcels. These parcels group together the development work done within a given workshop. You can ship these parcels to other workshops called client workshops.
A delivery is autonomous. Once the delivery development unit is compiled, a parcel is stored in the factory warehouse and has no more connection with the workshop where it was created. A parcel has its own directory structure.
All Open CASCADE Technology resources are seen as parcels.
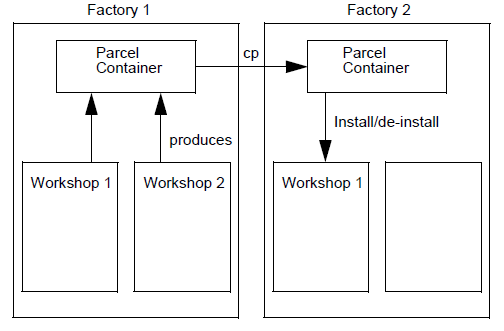
You are strongly advised to create delivery units under the root workbench of the workshop. Child workbenches could be deleted in the future, whereas the root workbench is likely to remain untouched. In other words, you safeguard the delivery by creating it in the root workbench.
Note If you do not specify a workbench when you make a delivery, it is created under the current workbench.
A workbench is generally the place where one particular developer or a team of developers works on a particular development. A workbench is composed of a public part and a private part.
The following roots are used in the structure of a workbench:
Roots are defined for each profile and platform supported by the workbench. For example, a workbench supporting the DFLT profile on Sun and SGI platforms has the following roots:
For a workbench additionally supporting ObjectStore, the following additional roots are also found: OBJS, OBJS_sun, OBJS_sil.
These roots are defined in the workbench definition file MyWorkbench.edl as the parameter %MyWorkbench_RootName.
Note that default values help to define various roots.
Under each root, a hierarchy of directories allows to store various files.
A workshop is an independent workspace inside which the complete cycle of software production is carried out. Workbenches inside a workshop are organized so that development units can be shared either by being published in a father workbench or by being placed in reference in the root workbench.
In a large-scale development that involves one or more teams of developers, you should decide how you are going to structure a workshop right at the beginning. If need be, you can review your decision later.
An existing workshop can be duplicated and the original workshop can be used as the basis for maintaining the present version of a product. The new workshop can then be used to develop and maintain a new version of the product.
When creating a new workshop, you specify - in the form of parcels – which resources are to be available within the workshop.
A factory contains a number of workshops and a warehouse. When Open CASCADE Technology is installed, the system administrator creates a single factory. This contains a single workshop as well as the warehouse containing OCCT resources in the form of parcels.
There is no theoretical limit to the number of workshops that can be added to a factory. However, a single factory should be enough.
The WOK interface is based on tcl, a command language provided by the Regents of the University of California and Sun Microsystems, Inc. The WOK development environment is in fact a tcl session.
Before you run a tcl session you must make sure that your account is configured for using tcl, see the Configuring Your Account for Tcl and WOK section.
To start a tcl session use the command:
Within this session, all WOK commands are available as well as standard tcl commands. You can also use tcl language extensions, if these are installed. To exit from a tcl session use the command:
Online help is provided with tcl. To access this, use the following command:
Online help is also available for all WOK commands. To display help on a particular WOK command, give the command name followed by the -h flag, as in the following example:
Implementation of an application is based on the following steps:
Note: Steps 1-3 can be performed with a single WOK command:
Before you start, the following restrictions on WOK entity names must be noted:
When you start work you go to the factory using the following command:
If you don’t want to work in a workshop already present in the factory, you can create a new one. To do this, use the following command:
This creates the new workshop MyWorkshop in the current factory. To create the same workshop in a different factory use the syntax below:
When you create a new workshop, it is empty.
When you create a workshop, you select existing OCCT resources, for example, parcels, to use in it. To do this, you create the workshop and add the parcels using the following syntax:
To display available OCCT resources, in other words, to see what parcels are available, you use the following command:
Note: parcel configuration rarely needs to change. If it does, only the workshop administrator should make them.
To open a workshop, you use the following command:
When you create a new workshop, it is empty. In other words, it does not contain any workbenches. To create the root workbench of a new workshop, you use the following command:
This creates a tree of workbench subdirectories. If workbenches already exist in your workshop, but you do not want to work in any of these, create a new workbench as a child of an existing one. You do this using the following syntax:
To open a workbench, you use the command below:
This automatically takes you to the root directory of the workbench
Before creating new data types, you should look for existing components that you can reuse. In particular, you should look through the existing resources of your Open CASCADE Technology platform to see if any of the required components already exist, or if any existing generic components can be suitably implemented. This search can be conducted using the online documentation. You should note the packages and classes, which you can reuse.
To develop new software components, you usually need to create one or more packages. You do this, by using the following command:
Because the key -p defines the default value for the ucreate command, you do not need to specify it. The following syntax, for example, will also create a package:
Enter the package or any other development unit structure using the wokcd command as in the syntax below:
The current directory is now:
Write the descriptions of the software components in CDL using an editor of your choice. Write each class in its own .cdl file and write one .cdl file (MyPackage.cdl) to specify the package that contains those classes.
Compile and check the package and its classes using:
This command also extracts the C++ header files (.hxx) and stores them in the derived files directory.
A package will contain methods, which may be:
You should not confuse this syntax with the template feature of C++ used to implement the genericity. The umake -o xcpp.template command creates a skeleton C++ file for:
To compile the package, use the command:
If you do not specify a package, the current development unit is compiled.
In the following example a workbench named MyWb is created as a child of an existing workbench Topo. MyWb is used for working on the package MyPack. Commands preceded by an asterisk below are used only once per session:
Note that umake command used without arguments will carry out all the above umake steps. You can also use it with specific arguments as above to go through the development process step by step.
The umake steps for development units of package type are explained below.
If your executable requires the use of a nocdlpack, create a development unit of nocdlpack type and move to its structure using the commands below:
Use an editor to write FILES, which is a nomenclature file for a nocdlpack. This file must list all the C, C++, Fortran, lex, and yacc sourcs files (one per line). Build the nocdlpack using the following command:
Note that a nocdlpack unit is not intended to perform tests. Use an executable unit instead.
In the following example a nocdlpack MyNocdlpack, is created. Commands preceded by an asterisk below are used only once per session:
The umake steps for development units of nocdlpack type are explained below.
If the application, which you intend to build, stores data in a file, you need to define a schema for the persistent data types that are known.
You create a schema and go to its root directory using the commands:
Using the editor of your choice, write a .cdl file to define the schema. This schema file lists all the packages that contain persistent data types used in the implementation of your application. It has the following format:
Compile and check the coherence of the CDL specification for the schema:
Extract the C++ description:
Compile the C++ description of the schema:
Alternatively, the above three steps can all be carried out by one command:
In the following example the schema MySchema is created. It contains all the schemas of the persistent classes of your own packages and the packages they depend on. Commands preceded by an asterisk below are used only once per session:
The umake steps for development units of schema type are explained below.
To make an executable from one or more of the packages, which you have created, write a .cdl file to specify the packages to use.
Refer to the CDL User’s Guide for full details. A simple example is given below.
Write the C++ file(s). For the example above you write two files: myexec.cxx and myex2.cxx.
To build the executable, use the command umake
In the following example an executable, MyExec, is created in the workbench MyWb. Commands preceded by an asterisk below are used only once per session:
| <Exec>.cdl | Primary executable file | | <AnExe>.cxx | Source C++ file | | <AnExe>_[1-9].cxx | Other source C++ files |
The umake steps for development units of executable type are explained below.
To test an executable, you create an executable development unit and move to its structure.
When you write the .cdl file for your test executable, specify the packages to test, for example:
Write the C++ test file(s), in the example, mytest1.cxx and mytest2.cxx.
To build the executable use the command:
To set up a test environment, move to the /drv subdirectory that corresponds to the current profile (e.g. /MyExec/drv/DFLT/sun) and run the executable test file.
The command wokenv is used with -s option to configure the test environment. The command wokenv –s uses the current workbench to decide what actions are needed to configure the tcl shell for use as your test environment. WOK sets the following environment variables:
After the environment is set up, you are at a C shell prompt and can run the executable.
Note Environment variables are only set when the command is used with the option -s. Thus, if you change a workbench or a factory within WOK and then return to the test environment you must use wokenv -s to ensure that the set environment variables configuration is correct for the current WOK state. The configuration actions that WOK performs can be written to a file and saved as a script. You can then edit this script to suit it to your own needs, and generate a personalized test environment.
To create the script file use the following command:
This command generates a file, ScriptFile, which configures a C shell to mirror the current WOK environment. An example script file is given below.
You create and enter a toolkit development unit using the following commands:
Using an editor, write a nomenclature file called PACKAGES which lists all the packages, one per line, that make up the toolkit. Add PACKAGES to FILES. Build the shareable library for this toolkit as follows:
Note: when one of the packages in the toolkit is modified, recompile the toolkit. A package should belong to one toolkit only.
In the following example, the toolkit TKMyToolkit is created. Commands preceded by an asterisk are used only once per session:
The umake steps for development units of toolkit type are explained below.
Building strategy depends on the platform. The following step sequences apply:
When executables are compiled, a TOOLKITS file is used to determine which toolkits are included. This file is located in the src directory of the entity being compiled. The process is as follows:
Toolkit substitution is performed as follows:
Here, for simplicity, assume that additional toolkits are not substituted for B, C and E.
Create a file named COMPONENTS in the src subdirectory of the delivery development unit. List in this file the prerequisites of the delivery and the components that are part of the delivery. Use the syntax shown below. Note that keywords and default options are shown in bold.
| Name | ParcelName | | Put path | | | Put include || |Put lib || | Requires | DeliveryName* | | Package | MyPack **[CDL][LIBRARY][INCLUDES][SOURCES]** | | Nocdlpack | MyNcdl **[LIBRARY][INCLUDES][SOURCES]** | | Executable | MyExec **[CDL][DYNAMIC][SOURCES]** | | Interface | MyIntf **[CDL][STUB_SERVER][SOURCES]** | | Client | MyClient **[CDL]**[STUB_CLIENT][SOURCES] | | Engine | MyEng **[CDL][DYNAMIC][SOURCES]** | | Schema | MyShma **[CDL][LIBRARY][SOURCES][DOC]** | | Toolkit |MyTk **[LIBRARY][SOURCES]** | | Get | DevelopmentUnitName::Type\:\:\:File |
If no keywords are specified then all default arguments shown in bold are taken into account. To select arguments, list the ones required explicitly. The arguments are explained below:
To build the delivery unit, use the command:
The result of building a delivery unit is a parcel, which can be installed in a warehouse and used by other workbenches.
In the following example a delivery is created, compiled and made into a parcel. Commands preceded by an asterisk below are used only once per session:
The umake steps for development units of type delivery are explained below.
You open the root workbench of the workshop where you want to install the parcel using the following command:
To install the parcel, use the following syntax:
There is a single umake step for development units of resource type.
To create an interface development unit and move to its structure, use commands:
Having created the interface, you select the classes and packages that you wish to make available for Java wrapping in the jni units. Use an editor of your choice to write a .cdl interface file that specifies these exported services. This file has the format:
To make the services of the interface available for further wrapping, build the interface, using the command:
In the following example a workbench, MyWb, is used for working on the interface MyInterface. Commands preceded by * (asterisk) are used only once during a session.
_<Interface>.cdl_ is the primary interface file.
The umake steps for development units of type interface are explained below.
Note Make sure you only use the src step of umake. Using umake without arguments will lead to an attempt of launching other steps relevant to the interface unit. However these steps will fail and anyway are not required for use in Java wrapping.
To create a development unit of type jni and move to its structure, use commands:
Use an editor to write a .cdl file that specifies the interface or interfaces required by the jni. This file has the following format:
To wrap services exported by the interfaces to Java, build the jni, using the command:
In the following example a workbench, MyWb, is used for working on the jni, MyJni. Commands preceded by * (asterisk) are used only once during a session.
Primary jni file is Jni.cdl
Derived Java files for a Jni are:
Derived C++ files for a Jni are:
The umake steps for development units of type jni are explained below.
There is a default user profile. If you wish to change this profile the command wokprofile is available.
An example profile is given below.
Parcel configuration rarely needs changes. However, if you do need to modify the list of resources, you can do so by editing the admin parameter file of the factory. This file is found in the admin directory of the factory and is named after the workshop. It has the suffix .edl. Its full name has the following format:
Move to the admin directory of the factory:
Then use the editor of your choice to edit the admin parameter file, MyWorkshop.edl. In this file, the parcel configuration is defined by an entry of the form:
The resources are listed within quotation marks. They are separated by spaces. Edit this list as required. Save the file and close it. To validate and take into account your changes use the command:
This command closes and reopens all the entities. Without the -a option, wokclose only applies to the current entity.
WOK provides sets of services, which can be grouped according to the entity they apply to:
All WOK commands follow a common naming convention. This is based on a set of common command names and a group of prefixes, which denote entity type. The command name takes a prefix representing the entity to which it applies. The following prefixes exist:
All command options are expressed using a dash (-) followed by one or more key letters and, if applicable, an argument. For example:
The compact version of this syntax is also valid:
This syntax conforms to the POSIX recommendations for UNIX commands. For all commands, there is a –h option, which displays help on usage.
The general syntax of the commands is presented in this document as follows:
Consequently, there are four general cases for a command:
Note a few commands described in this chapter do not completely respect this syntax; for example, create and rm.
As a rule, where an _<EntityPath>_ is given as an argument it specifies which entity the command applies to. Where no _<EntityPath>_ is specified, the command applies to the nearest appropriate entity. The create and rm commands are notable exceptions: you must specify an entity path with these commands.
General services are commands that apply to any entity manipulated by WOK. They are used for:
Navigates between different WOK entities and changes the current working directory. Without any arguments wokcd lists the current position (the WOK equivalent of ‘pwd’). With an argument, wokcd moves to the specified location. Options:
Possible values for <ParamSuffix> are: Home, Adm and Src. Use the following commands to change directories within a development unit:
wokcd - Lists the current position.
wokcd MODEL:GTI:gti:gp - Moves to the home directory of the gp package of the gti workbench in the GTI workshop in the MODEL factory.
wokcd -P Adm - Moves to the administration directory of the current entity.
Closes and reopens entities, i.e. reloads them into memory thus taking any changes into account. Option -a closes and reloads all entities.
Closes and reopens the current entity.
Closes and reopens all the entities.
Creates the file <ScriptFile>. This file is a script, which configures a C shell to mirror the current WOK environment. See the Test Environments section for more details. Options:
Generates the shell script MyTestEnvScript to configure a C shell so that it mirrors the current WOK environment.
Displays information about _<EntityPath>_. The information displayed is common to all the entities. If no _<EntityPath>_ is specified, information about the current entity is returned. This command can be used to find the path of a file. Options:
Returns the path of the source file gp.cdl in the MODEL:GTI:gti:gp.
Returns the development unit.
Using WorkbenchPath as the starting point, this command locates files associated with the development unit and specified by the argument argument. Options are:
Displays the location of the file, MyFile.
Queries system parameters such as variables and templates. For more information about parameters refer to the appendix Parameters and EDL Files at the end of this User’s Guide. If an <EntityPath> is specified this indicates the entity to which the command applies. Options:
Returns a list of directories used for parameters by the gti workbench.
Locates the nearest CSF.edl file used by the current entity.
Displays the value of the _%WOKUMake_Steps_ parameter in the gp package. The _%WOKUMake_Steps_ parameter contains a description of the steps used by umake.
Modifies session parameters. This command changes the mode of the current compilation and the profile of the current database. It also displays the current value of the session parameters. If no argument is specified, it displays the values of different parameters in the current session as well as the current position wokprofile -v. Options:
Displays all the session parameters.
Displays the current database profile.
Switches to optimized compilation and displays the parameters of the current session after the change has been made.
Switches to optimized compilation and displays the parameters of the current session after the change has been made. Note that the order in which these options are specified does not affect the result.
There is a dedicated list of commands for the management of factories. The commands to create and destroy factories are reserved for the exclusive use of the site administrator.
Reserved for administrator’s use
Creates a factory. The name of the factory to create is specified by EntityPath. You can also specify the entity that will contain the entity to be created.
Once the creation is completed, a file containing the parameters of the creation of the factory is created in the administration directory of the container to which the factory belongs.
Parameters: The following parameters are mandatory when a factory is created:
Options:
Returns a list of default values for the parameters that are mandatory when creating a factory.
Creates the factory MyFactory using default values for all mandatory parameters, except for Home, which is set to: /fred/myfactory
Displays details about the factory. If an EntityPath is specified this determines the factory to apply to. If no entity path is given, the command applies to the nearest factory. Options:
Displays a list of workshops in the nearest factory.
Displays the name of the warehouse in MyFactory.
Reserved for administrator’s use
Deletes the factory specified by EntityPath if it is empty.
Note, that you must not be in the factory you intend to destroy.
Deletes the factory MyFactory provided that it is empty.
A warehouse contains the parcels that are available in a factory. There is a dedicated list of commands for management of warehouses. The commands you use to create and destroy the warehouses are reserved for the exclusive use of the site administrator.
Reserved for administrator’s use.
Creates a warehouse. The name of the warehouse to create is given by *<WarehouseName>*. You can also specify the factory that will contain the warehouse. Once the creation is completed, a file containing the parameters of warehouse creation is in its turn created in the administration directory of the factory to which the warehouse belongs.
Parameters: The following parameters are mandatory when a warehouse is created:
Options:
Returns a list of default values for the parameters that are mandatory when creating a warehouse.
Creates the warehouse MyWarehouse using default values for all mandatory parameters.
Displays details about the warehouse and its contents. If an EntityPath is specified, this determines the warehouse to apply to. Option -p displays the parcels in the warehouse.
Displays a list of parcels in the current warehouse.
Reserved for Administrator’s Use.
Deletes the warehouse specified by EntityPath if it is empty. You should not be in the warehouse you intend to destroy.
Deletes the warehouse MyWarehouse provided that it is empty.
Reserved for administrator’s use
Declares the Parcel. This command adds the parcel to the list of parcels available in the warehouse House. Note that a factory has a default list of deliveries (which are represented by parcels) available to it. This list only needs to be modified when moving to a new version of the delivery. This is done using the Wdeclare command, and then by editing the .edl file of the appropriate workshop.
The following parameters are mandatory when declaring parcels:
Options:
Adds the parcel MyParcel to the warehouse MyWarehouse.
A parcel is a receptacle for development units. You use it to group together the units, which comprise a delivery unit. There is a dedicated list of commands for management of parcels. Only the site administrator should perform installation of parcels in a warehouse.
pinfo -<option> [<ParcelPath>] - displays details about the contents of the parcel. If ParcelPath is specified this determines the parcel to apply to. If no parcel path is specified the command applies to the nearest parcel.
Options:
Displays a list of units in the parcel MyParcel.
Reserved for administrator’s use
Installs the parcel <ParcelName> in the current warehouse. The process of installing a parcel sets up various paths and variables to ensure that the application can locate necessary resources and so on. The administrator must perform pinstall for each platform used.
Installs the parcel MyParcel in the current warehouse.
A workshop is a tree of workbenches using the same parcel configuration. There is a dedicated list of commands for management of workshops. The commands to create and destroy workshops are reserved for the exclusive use of the site administrator.
Reserved for administrator’s use
Creates a workshop, <WorkshopName>. You can also specify the factory that contains this workshop. Once the creation is completed, a file containing the parameters for the creation of the workshop is generated in the administration directory of the factory to which it belongs.
The following parameters are mandatory when creating a workshop:
Options:
Returns a list of default values for the parameters that are mandatory for creating a workshop.
Creates the workshop MyWorkshop in the factory MyFactory, using default values for all mandatory parameters.
Creates the workshop MyWorkshop in the factory MyFactory, using default values for all mandatory parameters except for ParcelConfig, which is set to Parcel1 Parcel2.
Displays details about the workshop. If WorkshopName is specified this determines the workshop this command is applied to. If no workshop is specified the command applies to the nearest workshop. Options:
Displays a list of workbenches in the nearest workshop.
Reserved for administrator’s use
Deletes the workshop <WorkshopName> if it is empty. You must not be in the workshop you intend to destroy.
Deletes the MyWorkshop provided that it is empty.
A workbench is the place where a developer (or a team of developers) works on a particular product. There is a dedicated list of commands for management of workbenches.
Creates the workbench <WBName> as a child of the workbench <ParentWB>. The result of this creation is a directory structure. Compared to the creation of other entities, creating a workbench requires an additional piece of information: you must specify the parent of the workbench to create. Once the creation is completed, a file containing the parameters of the creation of this workbench is created in the administration directory of the workshop that contains it. Parameters: The following parameters are mandatory when creating a workbench:
Options:
Returns a list of default values for the mandatory parameters to create a workbench.
Creates the workbench MyWorkbench using default values for all mandatory parameters. Note The –f option of this command is not obligatory. The system administrator can create the root workbench of a workshop without specifying a parent workbench.
The w_info command is the exception to the common command syntax. The form w_info is used instead of winfo because the latter already exists as a tcl/tk command and cannot be reused as a name by WOK. If <Workbench> is specified, this determines the workbench to apply to. If no <Workbench> is specified, the nearest workbench is used.
Using the tcl winfo command by mistake generates an error message, but does not cause any damage.
Options:
Returns a list of suppliers of the development unit MyDevUnit within the visibility of the current workbench.
Deletes the workbench, provided that it is empty and has no children. You must not be in a workbench you intend to destroy.
Deletes MyWorkbench, provided that it is empty and has no children.
Reserved for advanced use wmove -f <NewParentWorkbench> <Workbench> Moves the <Workbench> (and its children), to a different parent NewParentWorkbench within the same workshop. Option -f <argument> specifies the new parent workbench.
Moves the MyWorkbench under MyOtherWorkbench.
Allows automatic reconstruction of a workbench.
Options:
Compiles the whole workbench
The development unit is the basic building block of development work in the WOK environment. It is the base component of Open CASCADE Technology architecture. For a list of available types of development units refer to the Development Units section. There is a dedicated list of commands for management of development units.
Creates a development unit named <UnitName> of type <TypeCode>.
Once the creation is completed, a file containing the parameters of the creation of the development unit is generated in the administration directory of the workbench to which the development unit belongs.
TypeCodes:
Creates the development unit MyPackage in MyWorkbench. The unit is of package type.
Displays details about the development unit. Where no <UnitPath> is specified, details of the current unit are displayed. Filter options are available for use in conjunction with the options -f, -F, -p to filter the file list. Combinations of filter options can be used.
Note that the uinfo command is based on the results of construction using umake. As a consequence, the list of files displayed by uinfo is only valid if the construction has completed normally. Similarly, the list of files derived from the CDL is only valid if the CDLs of the unit have been translated successfully.
Options:
Displays the types, paths and names of all files associated with the unit.
Lists the names of the header files associated with the unit MyUnit which is in MyWorkbench.
Deletes the development unit <UnitPath> with its directory structure and its files, even if the unit is referenced by another one.
Deletes the development unit MyPack found in MyWorkBench.
Builds a development unit. The build process includes compilations, links, and various other actions, which make the development unit usable. The build process is specific for each type of development unit, refer to chapter 3 for details. The following properties apply:
Used without any arguments the umake command carries out all of the steps appropriate for the development unit to be constructed. Using keywords and arguments you can perform the build process step by step.
Options:
Builds the gp package.
The umake command is also used to specify build targets and extract C++ method prototypes. src, xcpp and obj units can be targeted. The syntax is explained below. For delivery units (for all options apart from *.list) the syntax is as follows:
This target computes a source file list as in the example below:
Extracts C++ header files. For -xcpp.* (with the exception of *.fill), the syntax is as follows:
You extract the method prototypes using the following command:
This syntax of umake command is only used with packages. It extracts the C++ prototypes of the methods of the classes contained in the package. The generated files are placed in the src directory of the current package. These files always have a .template suffix. With each extraction of a class, these files will contain all the methods of the class. Prototypes are extracted for:
Specifying the target, obj compiles the object files for one or more files. The syntax for -obj.* is as follows:
In a package, the following command executes all construction steps up to and including obj, doing for each of them only what is strictly necessary:
The following command will recompile all the primary sources of a package which are out of date:
You can use three levels of umake customization for a development unit.
Customization at this level involves setting parameters of existing umake steps using an .edl file. This file is taken into account each time umake is performed. It contains a series of assignments or appended variables used when creating the development unit. These commands can be preceded by instructions dedicated to the preprocessor in order to adjust its behavior within the actual context.
EXTERNLIB uses resources contained in Open CASCADE Technology prerequisites. To avoid referencing the path of these resources more than one time, the user may use the component EXTERNLIB to include these resources automatically via the link. The file contains the name of parameters, which are set independently.
The umake command does not generate actual dependencies. To avoid any cumbersome dependencies, for example, if you do not want the shareable library file for a package but the package enumeration only, use the INTERNLIB component listed in FILES, to get only the given dependencies.
In practice, the generated file, <myUD>.ImplDep, in the /drv/adm directory, is copied into INTERNLIB. INTERNLIB contains lines of enumerations, as below:
The example below illustrates how you can modify your WOK compiler options. Refer to Using EDL to Define WOK Parameters for an example of how to set link options as well as for more details about available parameters and .edl files.
The WOK umake command uses a dependency tree. This dependency tree is a graph that shows the umake steps, their inputs and their dependencies. You use it to perform the build, for example to ensure that only files, which have changed, and the files, which depend on these modified files, are recompiled.
This dependency tree is defined in an .edl file. The steps are listed in an order. Each is assigned a name and has its inputs specified. The output of one or more steps is the input to another step.
The following steps are standard for WOK umakes: src, src.list, exec.comp and exec.link. Any new step that you insert into the tree must be associated with a tcl program, which will be responsible for performing the step. You supply these tcl programs. For more details of tcl programming refer to the examples below and also to the Tcl Overview section.
The following example defines a umake dependency tree and introduces two new steps: exec.kerobj and exec.core. Each of these steps is then associated with a tcl program.
Customization at the tcl step level requires an understanding of the build process and the WOK dependency tree. Modification at this level is generally used to add elements to the build which are not described in the CDL. For example one possible use is to include external libraries or files into the final shareable library. Refer to Writing Tcl Steps for a WOK Build for more details.
You use the source management services to integrate source files between a root workbench and one of its children. The services are related to a particular workshop.
Prepares a report for integration to a reference (root) Workbench. This command prints a comparison of the state of source files contained in the specified units, <ud1,ud2,...,udN,> of the current workbench.
This workbench must be a direct descendant of the root workbench. If no unit names are specified, all the units in the workbench are processed. By default, the results of the comparison are printed to the standard output. The differences are computed in relation to the root workbench.
For each file, the status is indicated as follows:
Options:
This command manages the queue of pending reports. When a report is queued it is given a unique number also called a report-ID.
Options:
Possible options for –create are:
Queues the report ReportName and saves a copy of the files mentioned in the report. This copy will be used when the report is actually processed by the command wintegre.
Removes the report Report_ID from the queue, even if you do not own it.
Processes a report and removes it from the queue in the current workshop.
Parameters:
Options:
Note that the -nobase and -norefcopy options are mutually exclusive.
Uses the report whose ID is 1 to initialize the ref workbench with BaseNumber equal to 2.
Integrates the report whose ID is 1 to ref workbench.
Forces the integration of report 8. Use the –f option if you want report 8 to be processed first.
Edit the comment and modify /tmp/MyReport if required with current workbench accessed from ref workbench. You may use the -nobase option adding the following line in the VC.edl file (Adm of the concerned file):
The command has the following syntax:
The wnews command allows managing and using the data stored in the integration journal. The integration journal is updated via the command wintegre each time an integration is performed; it contains all the UDs and files concerned with the integration, as well as the comments provided by the developers (reports).
Every integration is numbered and the associated files are archived with a specific version number. Marks can be set on specific zones of the integrations via the wnews command. A mark is a character string which does not contain any dash character (-) and is associated with an integration number. Several marks may point to the same number, but one mark may only point to one number.
Note that BEGIN and END are reserved mark names. You cannot use them.
Options:
Additional options:
Wok provides a similar procedure wnews:cpwb, which allows to copy UDs from one workbench into another.
Note that you may access the associated code of this command by typing tclsh>cat $env(WOK_LIBRARY)/news_cpwb.tcl
For example, we can add the following to the file Me.tcl:
Then type the following commands:
Sets a mark on integration number 345
Sets a mark after the last integration performed
Lists all the marks set in the journal
Gets all the UDs modified between integrations INT_DEB and INT_END. Integration numbers and marks may be mixed as in the following:
Gets all the comments from the integrations between INT_DEB and INT_END
In a more elaborate way, a Tcl process may be called to get all information on the reports between INT_DEB and INT_END.
All modified files between n1 and n2 are copied from workbench w1 into workbench w2. New UDs are created in w2 if required If ulist is specified, only the UDs contained in this list are Processed. If notes is specified, all comments between n1 and n2 are written into this file.
The wget command allows importing source files into the workbench. The files are fetched from the SCCS database of the factory. This operation is known as a check-out operation. You can specify one or more files or a unit name. By default, the latest version of the files is fetched.
Options:
Fetches the latest version of File1.cxx and File2.hxx.
In the new WOK model:
The following procedure explains how to set up the source management environment for a workshop.
To integrate, proceed as follows:
A single session service is also available to allow you to query WOK. Sinfo command returns details of the WOK session.
Options:
Returns a list of WOK factories.
To ease the upgrade to the new version of WOK a number of aliases, compatible with the old version, have been set up. These convenience aliases include:
The following is an overall description of the IWOK main menu bar. Please, refer to the on-line help to get more detailed information on the various applications accessed via the graphic interface.

The main menu bar contains three menus:
The four icons on the left are used to access applications:




Note: for further information on CDL, refer to the CDL Reference Manual.
Click on the logo to either display or not the session in a window just below the main menu bar.
You may choose to display icons in the window, either in columns, with the last modified first, by date and size, or in rows.
Use the go up icon to navigate through the session and wokcd to update the window where the session was started.

The field Location gives the exact address of the item in the session. Use the arrow on the right to select already visited addresses.
Two types of popup menus may be accessed according to the context. Just click MB3 to display the popup menu.
Click on an item in the left window to get the popup menu providing access to applications.
In the right window you get the selection popup menu for the item types:
WOK is operated using the editor Emacs. Emacs is not provided in the Open CASCADE Technology distribution but is available from http://www.gnu.org/software/emacs/#Releases
A CDL mode has been created for Emacs. The .el file for this mode is not provided in the distribution, but is available on request from OPEN CASCADE.
|C-c |Command prefix | |TAB | cdl-tab | |DEL | backward-delete-character-untabify | |ESC | Command prefix | |C-c C-x | cdl-new-exception | |C-c C-e | cdl-new-enumeration | |C-c C-b | cdl-new-buffer | |C-c C-p | cdl-new-package | |C-c C-r | cdl-new-rubric | |C-c C-c | cdl-new-class | |C-c f | cdl-fill-mode | |C-c s | cdl-structure | |C-c t | cdl-tabsize | |C-c e | cdl-comment-end | |ESC k | cdl-find-class | |ESC q | cdl-comment-fill | |ESC TAB | cdl-untab | |ESC-RET | cdl-raw-newline |
EDL is a script-like programming language.
Comment - text, preceded by two hyphens.
!= || && file notfile defined notdefined
Templates The following template commands/keywords are available:
Miscellaneous The following miscellaneous commands exist:
The following conventions are used in the explanations below:
| *<Variable>* | refers to a variable, for example: *myvariable* | | *<Id>* | refers to an identifier, for example: myidentifier | | *“String”* | refers to a string of characters, for example: *“my string of characters”* | | *<Condition>* | refers to a condition, for example: *(mytest == “ok”) || (mytest == “good”)* | | *<Template>* | refers to the name of a template, for example: mytemplate. | |{} | indicates possible repetition of what is within the curly brackets. |
Concatenates the contents of the variables and strings on the right of the equals sign and assigns the result to the variable situated on the left. Using the operator ‘+=’ instead of ‘=’ adds the concatenation to the current contents of the variable on the left.
Sets <Variable> to the value “String”
Evaluates the template, <Template>, and sets <Variable> equal to this.
Runs an EDL file. The name of this file is either contained in the variable <Variable> or is given as a string, <String>.
Opens a file and associates it with the identifier <Id>. This <Id> identifies the file until it is closed. The name of the file is given as a string <String>, or using a variable <Variable>.
Writes the contents of the variable out to a file indicated by the file <Id>. This <Id> is the identifier allocated to the file when is opened using @file.
Closes the file identified by <Id>. This <Id> is the identifier allocated to the file when is opened using @file.
Concatenates the contents of the variables and strings and displays the result on standard out.
Checks for the existence of a file, the name of which is given in the string ‘String”, or else contained in the variable <Variable>. If the file exists, the instructions contained in the ‘then’ loop are executed up to the *@endif*, (or an @else if one is found before the @endif ). If the files do not exist, the ‘else’ loop is executed (if one exists).
Checks for the existence of a file, the name of which is given in the string ‘String”, or else contained in the variable <Variable>. If the file does not exist, the instructions contained in the ‘then’ loop are executed up to the @endif, (or an @else if one is found before the @endif). If the file does exist, the ‘else’ loop is executed (if one exists).
Checks for the existence of a variable or template, the name of which is given by <Template>, or else contained in the variable <Variable>. If a variable or a template by this name exists the instructions contained in the ‘then’ loop are executed up to the @endif, (or an @else if one is found before the @endif). If neither a variable nor a template exists, the ‘else’ loop is executed (if one exists).
Checks for the existence of a variable or template, the name of which is given by <Template>, or else contained in the variable <Variable>. If neither a variable nor a template by this name exists the instructions contained in the ‘then’ loop are executed up to the @endif, (or an @else if one is found before the @endif). If a variable or a template does exist, the ‘else’ loop is executed (if one exists).
Tests a condition. If the condition is true the instructions in the ‘then’ loop are executed up to the @endif, (or an @else if one is found before the @endif). If the condition is false, the ‘else’ loop is executed (if one exists).
Creates a template, which is a definition that contains variables. The variables on which a template relies are given in parentheses, following the name of the template. These variables are used to evaluate the template, and are referred to as ‘variables of evaluation’. When a template is evaluated (see @apply) the variables in its definition are replaced by the current values of the ‘variables of evaluation’. A template is re-evaluated each time it is used.
Adds the specified lines to an existing template.
Removes all the lines of a template.
Turns on the verbose mode, such that lines of text are displayed on standard out when you run EDL files.
Turns off the verbose mode, such that lines of text are not displayed on standard out when you run EDL files.
Conditions are used with *@if* commands. Complex and simple conditions are available. The syntax is similar to C++.
Simple conditions test for equality, the existence of a particular file and so on. The general format is:
The syntax of simple conditions is given below.
Complex conditions take into account the results of other conditions. Complex conditions use the operators || (logical OR) or the operator (logical AND). There are no restrictions on the formulation of these conditions: * (Simple condition) operator (Simple condition) * (Complex condition) operator (Simple condition) * (Simple condition) operator (Complex condition) * (Complex condition) operator (Complex condition)
For example,
WOK parameters are defined using EDL. There are two types of EDL parameters: Variables and Templates.
Variables have a ‘fixed’ value. By contrast a template relies on the values of other variables, and must re-evaluate itself each time it is used.
WOK parameters are grouped according to their class. The following classes exist: | CODEGEN | Code generator options, for example options for lex and yacc. | | CMPLRS | Compiler options. | | LDAR | Archive creation options. | | ARX | Archive extraction options. | | LDEXE | Executable linker options. | | LDSHR | Shared linker options. |
The WOK distribution includes a base configuration for each class of parameters. This base configuration is provided in the form of EDL files, one file per a class of parameters. Each file is named according to the parameter class:
This configuration file sets the values of all the parameters in the class.
For example, consider a parameter class FOO. There are two variable parameters in this class: FOO_Shared and FOO_Name. These two parameters are assigned a value in the FOO.edl file. The file is given as an example below:
Note that all the parameters in a class take the name of the class as a prefix to their own name. Parameters of type variable are also prefixed by % (percent symbol):
A simplified template definition is given as an example below. This definition is based on the FOO parameters set in the previous example above.
Let us define the variable parameter(s) to be used in the template and then the template itself:
Occasionally you may want to redefine WOK parameters. For example, you can change the compiler options to force ANSI mode compilation, or redefine how external libraries are referenced. Before redefining anything, decide on the scope of the redefinition. Is the redefinition to apply to the whole factory, a single workshop, a workbench, or just a development unit? In some cases you may want to redefine parameters within a delivery unit, so that a parcel is delivered with particular options.
The order in which redefinitions are applied (order of precedence) may mean your options are overwritten by subsequent redefinitions.
Each entity can have an associated redefinition file for each class of parameters. A redefinition file is an EDL file. It always takes the name of the entity to which it belongs, followed by the name of the class of parameters that it applies to:
For example, the file MyFactory_CMPLRS.edl redefines one of more of the parameters in the CMPLRS class. The scope of this redefinition is MyFactory. To be taken into account by WOK, this redefinition file must be created in the administration directory of the entity to which it belongs. To find out the pathname of this directory, use the command:
To test whether the file exists actually, use the command:
There is one exception to this rule for file placement. For a development unit, the redefinition file is treated as a *source *file, and consequently it must be located in the src directory of the unit. To find out the path of this directory, use the command:
One of the most common reasons to redefine WOK parameters is to modify compiler options. To do this, for example to add a compile option to the package MyPack:
WOK takes parameter (re)definitions into account in the following order.
To add a define for all C++ files compiled in the package MyPackage, MyPackage_CMPLRS.edl is declared in the development unit MyPackage This file contains:
In this example, a C code generator is used, which takes the input <file>.mygen and generates a <file>.c. The step obj.cgen automatically recognizes all files with the extension mygen and uses the generator on these files. The resulting .c files are compiled by the step obj.comp. The file MyUnit_CODEGEN.edl is written in a nocdlpack development unit MyUnit. This file contains the following code:
Tcl stands for ‘‘tool command language* and is pronounced ‘‘tickle*. It is actually two things: a language and a library.
As a simple textual language, tcl is intended primarily for issuing commands to interactive programs such as text editors, debuggers, illustrators, and shells. It has a simple syntax and is also programmable, so tcl users can write command procedures to provide more powerful commands than those in the built-in set.
As a library package, tcl can be embedded in application programs. The tcl library consists of a parser for the cl language, routines to implement the tcl builtin commands, and procedures that allow each application to extend tcl with additional commands specific to that application. The application program generates tcl commands and passes them to the tcl parser for execution. Commands may be generated by reading characters from an input source, or by associating command strings with elements of the application's user interface, such as menu entries, buttons, or keystrokes.
Download Tcltk 8.5 or 8.6 from http://www.tcl.tk/software/tcltk/8.6.html
A help application, tclhelp, is also provided with tcl and can be activated by command tclhelp.
The tcl interpreter offers WOK the following advantages:
The following tcl commands are most commonly used with WOK: expr, foreach, glob, if, package, proc, puts, set, source and unlink.
Refer to the tcl documentation, or the tcl help application, for details of these and other tcl commands.
To have access to WOK you must modify the configuration files of your account as described below.
To allow the C shell session to configure tcl add the following line to your .chsrc file:
To configure your account to allow access to WOK add the following line to your .cshrc file:
To enable configuration of the tcl interpreter, add the following line to your .tclshrc if it exists (if not create one):
The WOK_SESSIONID environment variable ensures that you start a new WOK session in the same state and with the same parameter values as your previous WOK session. This continuity is provided by using the same WOK_SESSIONID. Note that your WOK_SESSIONID does not change, unless you change it manually.
Make sure that WOK_SESSIONID points to (a subdirectory of) your home directory.
There are three advanced WOK commands available for writing umake steps in tcl:
msgprint [-i|-w|-e|-v|-V Class] prints a message. The output is directed to a WOK internal process that is in charge of printing messages.
The following options are available: | -i | Prints an information message. | | -w | Prints a warning message. | | -e | Prints an error message. | | -v | Prints a verbose message. | | -V<Class> | Prints a verbose message for class <Class>. | | -c | Prints context of message, i.e. the procedure that called it. |
For example,
Writes an error message, in format:
stepoutputadd <options> <OutputFileID> [<filepath>] adds an output file to the outputs of the step. This file is treated by subsequent steps in the same way as all the other output files of the step. The following options are available:
| -p<path> | Specifies the path where the file is located. | | -L | Output can be located (default). | | -N | Not a WOK file. Cannot be located. | | -F | Physical file (i.e. resides on a disk somewhere). | | -M | File is a member of the unit being built (default). | | -X | File is not a member of the unit being built. Not a WOK file. Cannot be located. | | -P | File is produced by this umake step (i.e. WOK can delete it because it will be regenerated). | | -R | File is not produced by this umake step (i.e. WOK must not delete it because it can not be regenerated). | -S<StepID> | Reserved for advanced use. Specifies stepID. | | -V | Reserved for advanced use. Virtual ‘file’ (i.e. an MSEntity). This option is used for passing keywords between steps for example. |
For example,
Adds the file */usr/myfiles/res.o* to the outputs of this step. Specifies that this file is not a WOK file, cannot be located automatically by WOK, and is not generated by this step. Here the full file path is used as the unique file identifier. This appears to be duplicated when it is also given as the physical location of the file.
stepaddexecdepitem <options> <InputFileID> <OutputFileID> adds a dependency between one file and another. Typically when introducing external object libraries the files are set to be dependent on the CDL file. We do this because the CDL file changes rarely, so the external files are not needlessly reprocessed, but they are always included in the final executable. The following options are available:
| -d | Adds a direct dependency (default). | | -i | Adds an indirect dependency. |
For example,
States that the file MyOutFile depends directly on the file MyInFile.
Each tcl umake step has the following components:
Execute processes each input file that is out of date (i.e. has changed since it was last processed, or depends on a file that has changed since it was last processed). Typically this procedure takes the form of a foreach loop. Argument: a development unit to process and a list of one or more arguments.
proc CCLKernel_core::AdmFileType {} { return stadmfile; } proc CCLKernel_core::OutputDirTypeName {} { return sttmpdir; } proc CCLKernel_core::HandleInputFile { ID } { scan $ID *%[^:]:%[^:]:%[^:]* unit type name switch $type { executable { return 1; } } switch $name { CCL_lelisp.ll { return 1; } } return 0; } proc CCLKernel_core::Execute { unit args } { global WOK_GLOBALS env msgprint -i -c CCLKernel_core::Execute Processing unit : $unit; msgprint -i -c CCLKernel_core::Execute set workbench [wokinfo -N $unit] set unitname [wokinfo -n $unit] set failed 0; set lispbin ** set lispfile ** set lispbinid ** set lispfileid ** foreach ID $args { scan $ID *%[^:]:%[^:]:%[^:]* Unit type name switch $type { executable { set lispbinid $ID set lispbin [stepinputinfo -p $ID] } } switch $name { CCL_lelisp.ll { set lispfileid $ID set lispfile [stepinputinfo -p $ID] } } } if { $lispfile == **} { set lispfileid CCLKernel:source:CCL_lelisp.ll; set lispfile [woklocate -p $lispfileid $workbench] } if { $lispbin == **} { msgprint -e -c CCLKernel_core::Execute Cannot find lelispbin in input return 1; } msgprint -i -c CCLKernel_core::Execute Using lelisp.bin at * $lispbin msgprint -i -c *CCLKernel_core::Execute set config *[wokparam -e Ilog_Home]/config* set tmpdir [wokinfo -p sttmpdir:. $unit] set output [wokinfo -p executable:. $unit] set lelisppointbin [wokinfo -p executable:lelisp.bin $unit] unlink -nocomplain $lelisppointbin link -sym $lispbin $lelisppointbin msgprint -i -c CCLKernel_core::Execute Setting Environment set WOK_GLOBALS(setenv_proc,tcl) 1 wokenv -s set WOK_GLOBALS(setenv_proc,tcl) 0 set olddir [pwd] cd [wokinfo -p source:. $unit] set FrontSIZE *-stack 12 -code 1500 -heap 2048 -number 0 -vector 32 -string 50 -symbol 30 -float 0 -cons * msgprint -i -c CCLKernel_core::Execute Exec : $config $tmpdir $lispbin $lispfile $output $FrontSIZE 8 puts exec /bin/env \ COREDIR=$output \ WBPACKAGE=[wokinfo -n $unit] ILOG_LICENSE_FILE=[wokparam -e Ilog_LicenseFile] \ CSF_EngineStarterList=/usr/local/etc/ EngineStarter.Hosts \ ILOG_LICENSE_FILE=[wokparam -e Ilog_LicenseFile] \ *FrontSIZE=$FrontSIZE* \ $config $tmpdir $lispbin $lispfile $output $FrontSIZE 8 msgprint -i -c CCLKernel_core::Execute [eval exec /bin/env \ COREDIR=$output \ WBPACKAGE=[wokinfo -n $unit] \ ILOG_LICENSE_FILE=[wokparam -e Ilog_LicenseFile] \ CSF_EngineStarterList=/usr/local/etc/ EngineStarter.Hosts \ *FrontSIZE=$FrontSIZE* \ $config $tmpdir $lispbin $lispfile $output $FrontSIZE 8] stepoutputadd -P
unitname.core stepaddexecdepitem -d $lispbinid
unitname.core stepaddexecdepitem -d $lispfileid
unitname.core cd $olddir return 0; } ~~~~~
 1.8.5
1.8.5